发布日期:2025-06-01 05:33 点击次数:108

 kaiyun官方网站官方客服24小时在线为您服务!
kaiyun官方网站官方客服24小时在线为您服务!
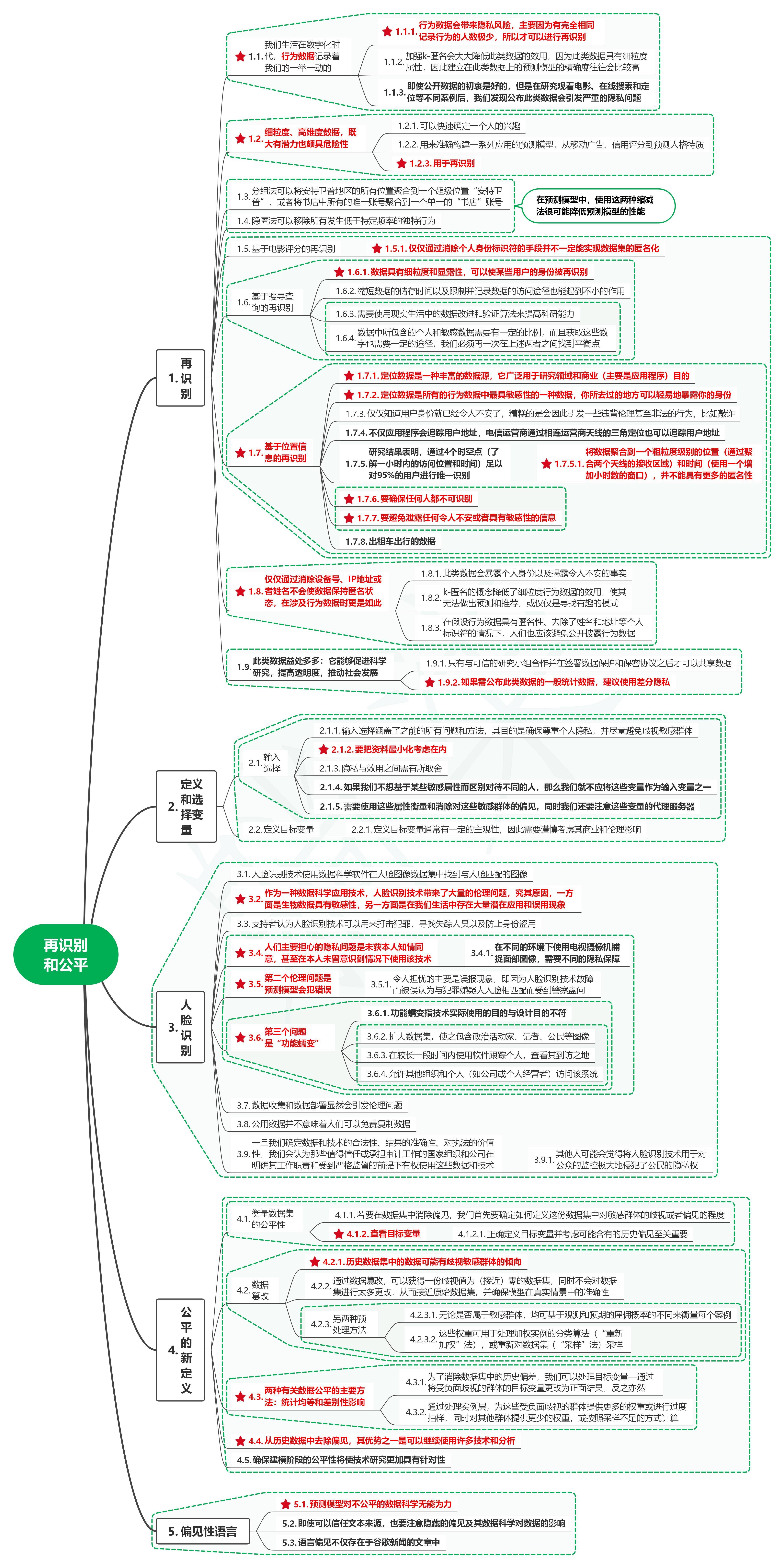
1.1. 咱们生涯在数字化期间,行动数据纪录着咱们的一坐通盘的
1.1.1. 行动数据会带来秘籍风险,主要因为有透顶沟通纪录行动的东说念主数小数,是以才不错进行再识别
1.1.2. 加强k-匿名会大大杜撰此类数据的效力,因为此类数据具有细粒度属性,因此确立在此类数据上的估量模子的精准度时时会相比高
1.1.3. 即使公开数据的初志是好的,可是在筹商不雅看电影、在线搜索和定位等不同案例后,咱们发现公布此类数据会激发严重的秘籍问题
1.2. 细粒度、高维度数据,既大有后劲也颇具危机性
1.2.1. 不错快速笃信一个东说念主的兴味
1.2.2. 用来准确构建一系列期骗的估量模子,从迁移告白、信用评分到估量东说念主格脾气
1.2.3. 用于再识别
1.3. 分组法不错将安特卫普地区的统共位置团员到一个超等位置“安特卫普”,或者将书店中统共的独一账号团员到一个单一的“书店”账号
1.4. 归隐法不错移除统共发生低于特定频率的特有行动
1.5. 在估量模子中,使用这两种缩减法很可能杜撰估量模子的性能
1.6. 基于电影评分的再识别
1.6.1. 只是通过排斥个东说念主身份标志符的妙技并不一定能竣事数据集的匿名化
1.7. 基于搜巡视询的再识别
1.7.1. 数据具有细粒度和清楚性,不错使某些用户的身份被再识别
1.7.2. 裁汰数据的储存期间以及终结并纪录数据的探访路线也能起到不小的作用
1.7.3. 需要使用实验生涯中的数据改造和考据算法来栽培科研才气
1.7.4. 数据中所包含的个东说念主和敏锐数据需要有一定的比例,并且获取这些数字也需要一定的路线,咱们必须再一次在上述两者之间找到均衡点
1.8. 基于位置信息的再识别
1.8.1. 定位数据是一种丰富的数据源,它平庸用于筹商范畴和贸易(主若是期骗环节)主见
1.8.2. 定位数据是统共的行动数据中最具敏锐性的一种数据,你所去过的所在不错拖拉地高慢你的身份
1.8.3. 只是知说念用户身份就照旧令东说念主不安了,倒霉的是会因此激发一些抵触伦理致使罪犯的行动,比如绑架
1.8.4. 不仅期骗环节会追踪用户地址,电信运营商通过连络运营商天线的三角定位也不错追踪用户地址
1.8.5. 筹商效率标明,通过4个时空点(了解一小时内的探访位置和期间)足以对95%的用户进行独一识别
1.8.5.1. 将数据团员到一个粗粒度级别的位置(通过团员两个天线的接受区域)和期间(使用一个增多小时数的窗口),并弗成具有更多的匿名性
1.8.6. 要确保任何东说念主皆不可识别
1.8.7. 要幸免泄露任何令东说念主不安或者具有敏锐性的信息
1.8.8. 出租车出行的数据
1.9. 只是通过排斥斥地号、IP地址或者姓名不会使数据保握匿名现象,在波及行动数据时更是如斯
1.9.1. 此类数据会高慢个东说念主身份以及揭露令东说念主不安的事实
1.9.2. k-匿名的看法杜撰了细粒度行动数据的效力,使其无法作念出估量和推选,或只是是寻找意旨兴趣意旨兴趣的口头
1.9.3. 在假定行动数据具有匿名性、去除了姓名和地址等个东说念主标志符的情况下,东说念主们也应该幸免公开袒露行动数据
1.10. 此类数据益处多多:它省略促进科学筹商,栽培透明度,鼓舞社会发展
1.10.1. 只须与的确的筹商小组合营并在签署数据保护和守密公约之后才不错分享数据
1.10.2. 如果需公布此类数据的一般统计数据,提议使用差分秘籍
2. 界说和选拔变量2.1. 输入选拔
2.1.1. 输入选拔涵盖了之前的统共问题和圭表,其主见是确保尊重个东说念主秘籍,并尽量幸免敌视敏锐群体
2.1.2. 要把府上最小化接头在内
2.1.3. 秘籍与效力之间需有所采用
2.1.4. 如果咱们不念念基于某些敏锐属性而区别对待不同的东说念主,那么咱们就不应将这些变量动作输入变量之一
2.1.5. 需要使用这些属性议论和排斥对这些敏锐群体的偏见,同期咱们还要庄重这些变量的代理作事器
2.2. 界说主见变量
2.2.1. 界说主见变量接续有一定的主不雅性,因此需要严慎接头其贸易和伦理影响
3. 东说念主脸识别3.1. 东说念主脸识别时刻使用数据科学软件在东说念主脸图像数据聚拢找到与东说念主脸匹配的图像
3.2. 动作一种数据科学期骗时刻,东说念主脸识别时刻带来了多数的伦理问题,究其原因,一方面是生物数据具有敏锐性,另一方面是在咱们生涯中存在多数潜在期骗和误用风光
3.3. 撑握者认为东说念主脸识别时刻不错用来打击不法,寻找失散东说念主员以及留神身份盗用
3.4. 东说念主们主要挂牵的秘籍问题是未获本东说念主知情欢跃,致使在本东说念主未始意志到情况下使用该时刻
3.4.1. 在不同的环境下使用电视录像机捕捉面部图像,需要不同的秘籍保险
3.5. 第二个伦理问题是估量模子会犯造作
3.5.1. 令东说念主担忧的主若是误报风光,即因为东说念主脸识别时刻故障而被误认为与不法嫌疑东说念主东说念主脸相匹配而受到视察征询
3.6. 第三个问题是“功能蠕变”
3.6.1. 功能蠕变指时刻实质使用的主见与缠绵主见不符
3.6.2. 扩大数据集,使之包含政事步履家、记者、公民等图像
3.6.3. 在较长一段期间内使用软件追踪个东说念主,搜检其到访之地
3.6.4. 允许其他组织和个东说念主(如公司或个东说念主筹谋者)探访该系统
3.7. 数据网罗和数据部署昭彰会激发伦理问题
3.8. 公用数据并不虞味着东说念主们不错免费复制数据
3.9. 一朝咱们笃信数据和时刻的正当性、效率的准确性、对公法的价值性,咱们会认为那些值得信任或承担审计使命的国度组织和公司在明确其使命职责和受到严格监督的前提下有权使用这些数据和时刻
3.9.1. 其他东说念主可能会合计将东说念主脸识别时刻用于对公众的监控极地面骚动了公民的秘籍权
4. 平正的新界说4.1. 议论数据集的平正性
4.1.1. 若要在数据聚拢排斥偏见,咱们最初要笃信若何界说这份数据聚拢对敏锐群体的敌视或者偏见的进度
4.1.2. 搜检主见变量
4.1.2.1. 正确界说主见变量并接头可能含有的历史偏见至关蹙迫
4.2. 数据点窜
4.2.1. 历史数据聚拢的数据可能有敌视敏锐群体的倾向
4.2.2. 通过数据点窜,不错得回一份敌视值为(接近)零的数据集,同期不会对数据集进行太多革新,从而接近原始数据集,并确保模子在信得过情景中的准确性
4.2.3. 另两种预不断圭表
4.2.3.1. 不管是否属于敏锐群体,均可基于不雅测和预期的雇佣概率的不同来议论每个案例
4.2.3.2. 这些权重可用于不断加权实例的分类算法(“重新加权”法),或重新对数据集(“采样”法)采样
4.3. 两种关连数据平正的主要圭表:统计均等和鉴别性影响
4.3.1. 为了排斥数据聚拢的历史偏差,咱们不错不断主见变量—通过将受负面敌视的群体的主见变量革新为正面效率,反之也是
4.3.2. 通过不断实例层,为这些受负面敌视的群体提供更多的权重或进行过度抽样,同期对其他群体提供更少的权重,或按照采样不及的神志筹商
4.4. 从历史数据中去除偏见,其上风之一是不错络续使用好多时刻和分析
4.5. 确保建模阶段的平正性将使时刻筹商愈加具有针对性
5. 偏见性话语5.1. 估量模子对对抗正的数据科学窝囊为力
5.2. 即使不错信任文蓝本源,也要庄重遮掩的偏见偏执数据科学对数据的影响
5.3. 话语偏见不仅存在于谷歌新闻的著述中kaiyun官方网站官方客服24小时在线为您服务!
Powered by 开云集团「中国」Kaiyun·官方网站 @2013-2022 RSS地图 HTML地图