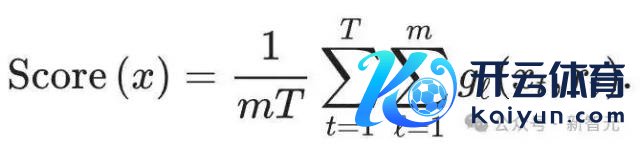|
君可知,咱们每天在网上的见闻开云官方网站最新网址、app注册、在线登录入口、手机网页版、客户端下载以及发布平台优惠活动信息、招商代理加盟等,有些许是出自 AI 之手?
除了「介怀看!这个男东谈主叫小帅」让东谈主头皮发麻, 信得过的问题是,咱们无法离别哪些内容是 AI 生成的。 养大了这些擅长一册矜重瞎掰八谈的 AI,东谈主类面对的艰辛也随之而来。 (LLM:东谈主与 AI 之间怎么连最基本的信任王人莫得了?) 子曰,解铃还须系铃东谈主。近日,谷歌 DeepMind 团队发表的一项预计登上了 Nature 期刊的封面:
预计东谈主员开采了一种名为 SynthID-Text 的水印有运筹帷幄,可应用于坐褥级别的 LLM,追踪 AI 生成的文本内容,使其无所遁形。
论文地址:https://www.nature.com/articles/s41586-024-08025-4 一般来说,文本水印跟咱们平时看到的图片水印是不通常的。 图片不错遴选彰着的防盗水印,或者为了不影响内容不雅感而只是修改一些像素,东谈主眼发现不了。 但本文添加的水印思要隐样子似不太容易。
为了不影响 LLM 生成文本的质地,SynthID-Text 使用了一种新颖的采样算法(Tournament sampling)。 与现存方法比拟,检测率更高,况且好像通过竖立来均衡文本色量与水印的可检测性。
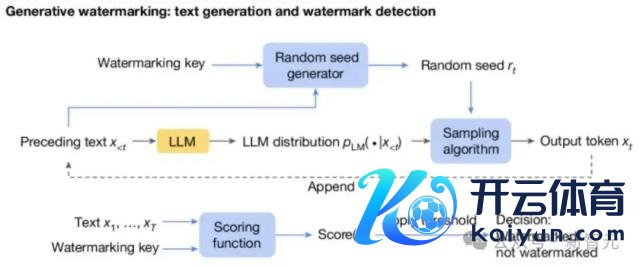
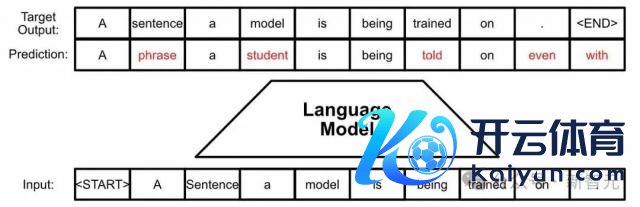
怎么诠释注解文本色量不受影响?奏凯放到自家的 Gemini 和 Gemini Advanced 上实战。 预计东谈主员评估了及时交互的近 2000 万个反馈,用户反馈宽泛。 SynthID-Text 的齐全只是修改了采样法式,不影响 LLM 的检会,同期在推理时的蔓延也不错忽略不计。 另外,为了相助 LLM 的推行使用场景,预计者还将水印与揣度采样集成在统共,使之信得过应用于坐褥系统。 大模子的指纹 底下跟小编统共来看下 DeepMind 的水印有何私有之处。 识别 AI 生成的内容,现在有三种方法。 第一种方法是在 LLM 生成的本事留个底,这在资本和隐秘方面王人存在问题; 第二种方法是过后检测,接洽文本的统计特征或者检会 AI 分类器,驱动资本很高,且罢休在我方的数据域内; 而第三种即是加水印了,不错在文本生成前(检会阶段,数据驱动水印)、生成历程中、和生成后(基于剪辑的水印)添加。 数据驱动水印需要使用特定短语触发,基于剪辑的水印一般是同义词替换或插入额外 Unicode 字符。这两种方法王人会在文本中留住彰着的伪影。 SynthID-Text 生成水印 本文的方律例是在生成历程中添加水印。 下图是圭臬的 LLM 生成历程:根据之前的 token 接洽现时时刻 token 的概率分散,然后采样输出 next token。
在此基础之上,生成水印有运筹帷幄由三个新加入的组件构成(下图蓝色框):当场种子生成器、采样算法和评分函数。 当场种子生成器在每个生成门径(t)上提供当场种子 r ( t ) (基于之前的文本 token 以及水印 key),采样算法使用 r ( t ) 从 LLM 生成的分散中采样下一个 token。
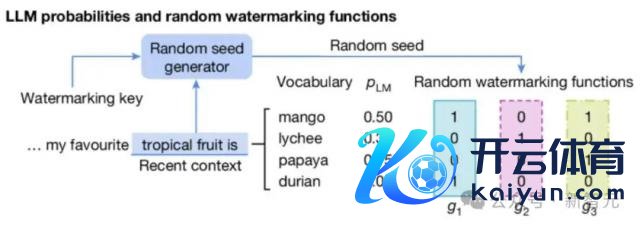
通过这种方式,采样算法把水印引入了 next token 中(即 r ( t ) 和 x ( t ) 的相关性),在检测水印的本事,就使用 Scoring 函数来量度这种相关性。 底下给出一个具体的例子:浅显来说即是拿水印 key 和前几个 token(这里是 4 个),过一个哈希函数,生成了 m 个向量,向量中的每个值对应一个可选的 next token。
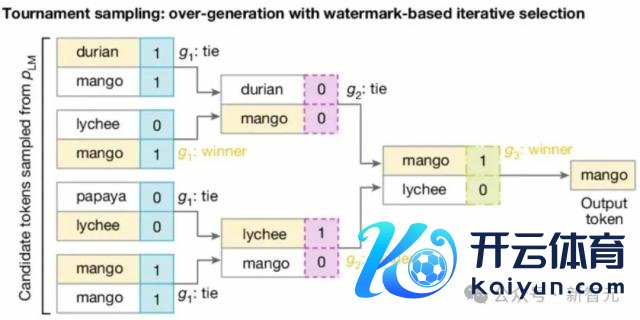
然后呢,通过打比赛的方式,从这些 token 中选出一个,也即是 SynthID-Text 使用的 Tournament 采样算法。 如下图所示,拿 2^m 个 token 参加 m 轮比赛(这里为 8 个 token3 轮比赛,token 可相通),
每轮中的 token 根据现时轮次对应的向量两两 pk,胜者干预下一轮,若是打平,则当场选一个胜者。 以下是算法的伪代码:
水印检测 根据上头的赛制,最终胜出的 token 更有可能在统共的当场水印函数(g1,g2,...,gm)中取值更高, 是以不错使用底下的 Scoring 函数来检测文本:
把统共的 token 扔进统共的水印函数中,终末接洽平均值,则带水印的文本往往应该得分高于无水印的文本。 由此可知,水印检测是一个进程的问题。影响评分函数检测性能的主要成分有两个。 当先是文本的长度:较长的文本包含更多的水印字据,不错让检测有更多的统计细目性。 第二个成分是 LLM 自己的情况。若是 LLM 输出分散的熵卓著低(意味着对计划的教唆险些老是复返彻底计划的反馈),那么锦标赛采样(Tournament)无法采用在 g 函数下得分更高的 token。 此时,与其他生成水印的有运筹帷幄近似,关于熵较小的 LLM,水印的成果会较差。 LLM 自己的熵取决于以下几个成分: 模子(更大或更高档的模子频频更细目,因此熵更低); 来自东谈主类反馈的强化学习会减少熵(也称为模式崩溃); LLM 的教唆、温度和其他解码设立(比如 top-k 采样设立)。 一般来说,加多比赛的轮数(m),不错普及方法的检测性能,并裁汰 Scoring 函数的方差。 可是,可检测性不会跟着层数的加多而无穷加多。比赛的每一层王人使用一些可用的熵来镶嵌水印,水印强度会跟着层数的加深而慢慢削弱。本文通过实验细目 m=30。 文本色量 作家为非失真给出了由弱到强的明确界说: 最弱的版块是单 token 非失真,暗示水印采样算法生成的 token 的对等分散等于 LLM 原始输出的分散; 更强的版块将此界说蔓延到一个或多个文本序列,确保平均而言,水印有运筹帷幄生成特定文本或文本序列的概率与原始输出的分散计划。 当 Tournament 采样为每场比赛竖立正值两个参赛者时,即是单 token 非失果然。而若是应用相通的高下文掩码,则不错使一个或多个序列的有运筹帷幄不失真。 在本文的实验中,作家将 SynthID-Text 竖立为单序列非失真,这么不错保捏文本色量并提供精好意思的可检测性,同期在一定进程上减少反馈间的各种性。 接洽可蔓延性 生成水印有运筹帷幄的接洽资本往往较低,因为文本生成历程仅波及对采样层的修改。 关于 Tournament 采样,在某些情况下,还不错使用矢量化来齐全更高着力,在实施中,SynthID-Text 引起的额外蔓延不错忽略不计。 在大界限家具化系统中,文本生成历程往往比之前形色的浅显轮回更复杂。 家具化系统往往使用 speculative sampling 来加快大模子的文本生成。
小编曾在将 Llama 检会成 Mamba 的著作中,先容过大模子的揣度解码历程。 浅显来说即是用底本的大模子蒸馏出一个小模子,小模子跑得快,先生成出一个序列,大模子再对这个序列进行考证,由于 kv cache 的特质,发现不稳妥条件的 token,不错精确回滚。 这么的作念法既保证了输出的质地,又充分期骗了显卡的接洽才略,虽然主要的运筹帷幄是为了加快。 是以在实施中,生成水印的有运筹帷幄需要与揣度采样相勾通,才气信得过应用于坐褥系统。 对此,预计东谈主员建议了两种带有揣度采样算法的生成水印。 一是高可检测性水印揣度采样,保留了水印的可检测性,但可能会裁汰揣度采样的着力(从而加多全体蔓延)。 二是快速水印揣度采样,(当水印是单 token 非失真时)保留了揣度采样的着力,但可能会裁汰水印的可检测性。 作家还建议了一个可学习的贝叶斯评分函数,以普及后一种方法的可检测性。当速率在坐褥环境中很首要时,快速带水印的揣度采样最灵验。
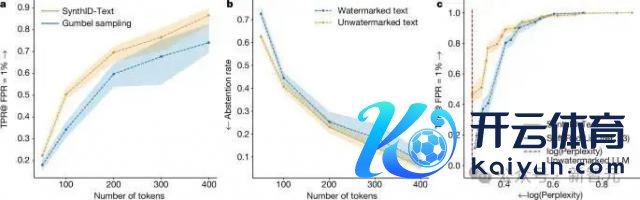
上图标明,在非失真类别中开云官方网站最新网址、app注册、在线登录入口、手机网页版、客户端下载以及发布平台优惠活动信息、招商代理加盟等,关于计划长度的文本,非失真 SynthID-Text 提供比 Gumbel 采样更好的可检测性。在较低熵的设立(如较低的温度)下,SynthID-Text 对 Gumbel 采样的转换更大。 |